간단한 예제로 칼만 필터를 어떻게 설계하고 구현하는지 직접 경험해 보자. 예제는 다음과 같다.
“배터리의 전압을 측정하는데, 잡음이 심해서 잴 때마다 달랐다. 그래서 칼만 필터로 측정 데이터의 잡음을 제거해보기로 했다. 전압은 0.2초 간격으로 측정한다.”
10.1 시스템 모델
칼만 필터를 설계하려면 가장 먼저 시스템 모델을 알아야 한다. 주어진 시스템 모델은 배터리의 전압을 상태변수($x_k$)로 하는 다음과 같은 시스템 모델이다.
시스템 모델에는 정답이 없다. 최대한 실제 시스템과 비슷해야 한다는 원칙만 있다. 그럼 식 $\ref{10.1}$의 시스템 모델이 실제 시스템을 제대로 반영하고 있는지 확인해 보자.
첫 번째 식은 배터리의 전압이 어떻게 변해가는지를 나타내는 식이다. 배터리의 전압은 일정하게 유지되는데($x_{k+1} = x_k$), 그 값은 $14$ 볼트($x_{0}=14$)라는 뜻이다. 보통 배터리는 대부분 전압이 일정하게 유지된다. 짧은 시간에 급격하게 변하는 경우는 별로 없다. 따라서 식 $ref{10.1}$은 나름 타당한 모델로 볼 수 있다.
두 번째 식은 전압이 측정값인데 여기에는 잡음($v_k)$이 섞여 있다는 의미를 담고 있다. 그리고 측정 잡음의 특성을 표현한 $v_k = N(0,2^2)$의 의미는 평균이 $0$ 이고, 표준편차가 $2$ 인 정규분포를 따르는 신호라는 뜻이다. 우선 측정값이 전압이라는 사실은 잘 반영됬다. 그런데 잡음의 특성이 정확한지는 신호와 센서를 분석해야 한다. 해석적 접근이 여의치 않다면, 시스템 모델 $R$을 설계 변수로 보고 값을 바꿔가면서 적절한 값을 선정하는 것도 한 방법이다.
이제 칼만 필터를 구현해 보겠다. 제일 먼저 시스템 모델을 구성하는 $A, H, Q, R$을 구해야 한다. 식 $8.1$과 $8.2$의 시스템 모델식을 식 $\ref{10.1}$과 비교해보면 이 네 변수의 값은 쉽게 알 수 있다.
여기서 $Q$가 $0$인 이유는 $w_k$가 없기 때문이다. $w_k$가 없다는 말은 $w_k = 0$ 이라는 의미이므로 분산이 $0$인 것은 당연하다.
다음으로 할 일은 초기 예측값을 정하는 것이다. 이 예제에서는 다음과 같이 선정했다. 초기값에 대한 정보가 전혀 없다면 오차 공분산을 크게 잡는게 좋다.
10.2 칼만 필터 함수
이제 사전 준비는 모두 끝났다. 아래는 칼만 필터 알고리즘을 구현한 SimpleKalman 함수의 코드이다. 이 함수는 측정값을 인자로 받아 추정 전압을 반환한다. 소스 코드는 간단하다. 뒤에 나오는 복잡한 예제에서도 칼만 필터 함수의 구조는 거의 변하지 않는다. 문제가 복잡해지면 시스템 모델만 복잡해질 뿐, 칼만 필터 구현 자체는 거의 달라지지 않는다.
SimpleKalman.m
function [ volt ] = SimpleKalman(z)
% 간단한 칼만필터 함수
% 입력 z , 출력 volt
persistent A H Q R
persistent x P
persistent firstRun
if isempty(firstRun)
A = 1;
H = 1;
Q = 0;
R = 4;
x = 14;
P = 6;
firstRun=1;
end
xp = A*x; % I. 추정값 예측
Pp = A*P*A'+Q; % 오차 공분산 예측
K = Pp*H'*inv(H*Pp*H' + R); % II. 칼만 이득 계산
% 참고로 inv 대신 /사용 가능
x = xp+K*(z-H*xp); % III. 추정값 계산
P = Pp - K*H*Pp; % IV. 오차 공분산 계산
volt = x;
end
구현 코드를 보면 시스템 모델 변수는 함수가 최초로 실행될 때 한번만 초기화된다. 초기 예측값도 이 때 지정한다. 반면 이 변수들을 내부에서 초기화하지 않고, 함수의 인자로 받도록 구현하는 경우도 있다.
SimpleKalman 함수는 5장 그림의 과정을 그대로 따라 구현했다. 변수명도 되도록 알고리즘에서 사용하는 이름과 일치시켰다. 예측값을 나타내는 변수만 윗첨자 대신 이름 뒤에 $p$를 붙였다. 그리고 각 과정 옆에 주석을 달아 이해하기 쉽게 하였다.
10.3 테스트 프로그램
아래 TestSimpleKalman.m은 앞 절의 SimpleKalman 함수를 검증하기 위한 테스트 프로그램이다. 프로그램 구조는 1장의 TestAvgFilter.m과 거의 똑 같다. 평균 필터의 AvgFilter 함수 대신 칼만 필터 함수인 SimpleKalman을 호출하는 정도만 다르다.
TestSimpleKalman.m
clear all
dt = 0.2;
t = 0:dt:10;
Nsamples = length(t);
Xsaved = zeros(Nsamples, 1);
Zsaved = zeros(Nsamples, 1);
for k=1:Nsamples
z = GetVolt();
volt = SimpleKalman(z);
Xsaved(k) = volt;
Zsaved(k) = z;
end
figure
plot(t,Xsaved,'o-')
hold on
plot(t,Zsaved,'r:*')
xlabel('Time[sec]');
ylabel('Voltage[V]');
GetVolt.m
function [ z ] = GetVolt()
% 전압을 읽어오는 함수
% 평균 14.4 볼트, 잡음이 섞여있음 잡음의 평균은 0 이고 표준편차가 4
w = 0 + 4*randn(1,1);
z = 14.4 + w;
end
아래 그림은 칼만 필터로 처리한 추정값 그래프이다. 그림에서 실선이 칼만 필터로 추정한 전압이고, 점선은 측정값이다. 측정 잡음 때문에 측정값이 상당히 넓게 퍼져 있다. 반면에 칼만 필터 출력은 상대적으로 참 값($14.4 V$) 주위에 모여 있다. 칼만 필터가 측정 잡음을 제거해 추정값이 참 값에 근접했기 때문이다.
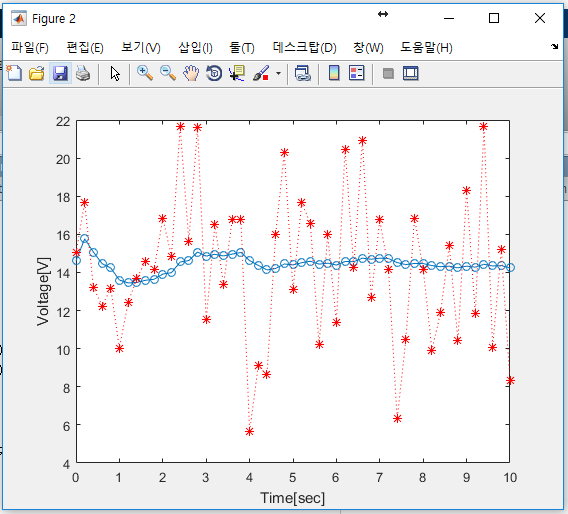
10.4 오차 공분산과 칼만 이득
칼만 필터 함수를 수정해 추정 전압 외에 오차 공분산과 칼만 이득도 함께 반환하도록 하겠다. 아래 SimpleKalman2 함수에 구현을 하였다. 테스트 프로그램은 각 루프마다 측정값과 추정값 외에 칼만 이득($K_k$)과 오차 공분산($P_k$)도 함께 저장하도록 수정했다.
SimpleKalman2.m
function [ volt Px K ] = SimpleKalman2(z)
% 간단한 칼만필터 함수
% 입력 z , 출력 volt P K
persistent A H Q R
persistent x P
persistent firstRun
if isempty(firstRun)
A = 1;
H = 1;
Q = 0;
R = 4;
x = 14;
P = 6;
firstRun=1;
end
xp = A*x; % I. 추정값 예측
Pp = A*P*A'+Q; % 오차 공분산 예측
K = Pp*H'*inv(H*Pp*H' + R); % II. 칼만 이득 계산
% 참고로 inv 대신 /사용 가능
x = xp+K*(z-H*xp); % III. 추정값 계산
P = Pp - K*H*Pp; % IV. 오차 공분산 계산
volt = x;
Px = P;
end
TestSimpleKalman2.m
clear all
dt = 0.2;
t = 0:dt:10;
Nsamples = length(t);
Xsaved = zeros(Nsamples, 3);
Zsaved = zeros(Nsamples, 1);
for k=1:Nsamples
z = GetVolt();
[volt Cov Kg] = SimpleKalman2(z);
Xsaved(k,:) = [ volt Cov Kg ];
Zsaved(k) = z;
end
figure
plot(t, Xsaved(:,1), 'o-')
hold on
plot(t, Zsaved, 'r:*')
xlabel('Time [sec]')
ylabel('Voltage [V]')
legend('Kalman Filter', 'Measurements')
figure
plot(t, Xsaved(:,2), 'o-')
xlabel('Time [sec]')
ylabel('P')
figure
plot(t, Xsaved(:,3), 'o-')
xlabel('Time [sec]')
ylabel('K')
아래는 실행 결과이다. TestSimpleKalman2.m도 TestSimpleKalman과 비슷한 결과를 보여준다.
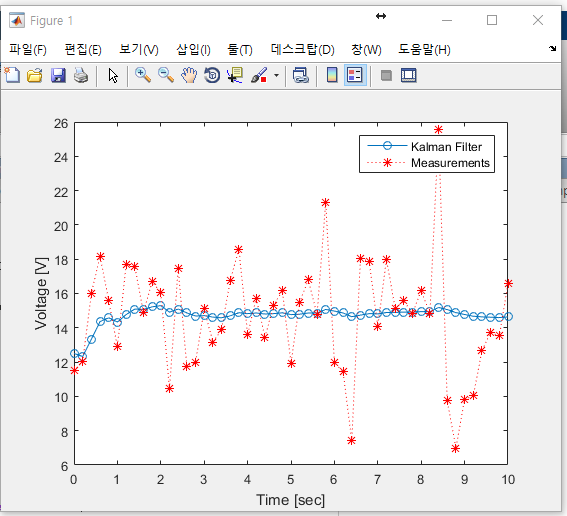
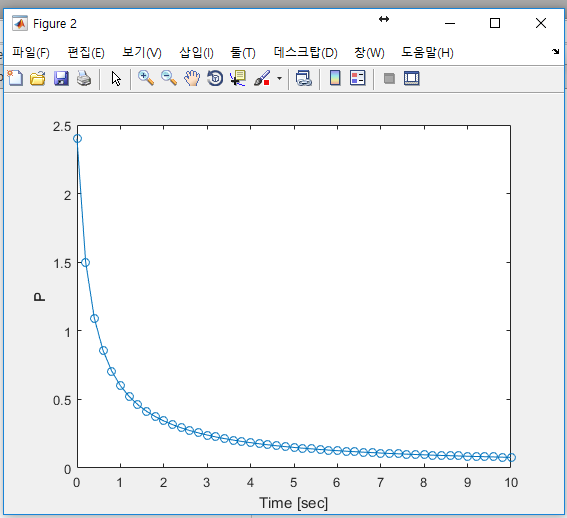
먼저 오차 공분산의 변화를 살펴 보겠다. 시간이 지나갈수록 오차 공분산 값이 꾸준히 작아진다. 그런데 처음에는 아주 빠른 속도로 줄어들다가 차츰 느려져서 나중에는 거의 줄어들지 않는다. 오차 공분산이 줄어드는 것은 추정값의 오차가 작아진다는 말과 같다. 오차가 줄어드는 속도가 느려지는 까닭은 추정값의 오차가 줄어들 만큼 줄어들었기 때문이다. 즉, 추정값의 오차가 충분히 작아서 더 이상 줄어들 여지가 없는 상태로 수렴했다는 뜻이기도 하다.
아래 그림으로 시간에 따른 오차 공분산의 변화를 볼 수 있다.
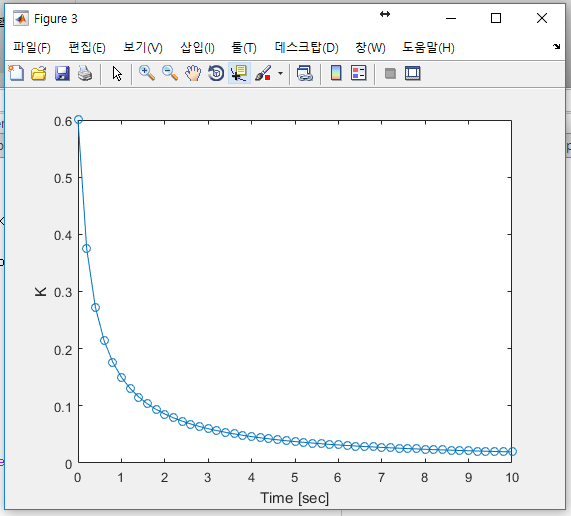
칼만 이득 그래프도 비슷한 경향을 보인다. 처음에는 아주 빠른 속도로 줄어들다가 차츰 느려져서 나중에는 거의 일정한 값을 유지한다. 그럼 칼만 이득이 작아진다는 것이 어떤 의미인지 알아보자. 칼만 필터의 추정값 계산식을 다시 옮겨 써 보겠다.
위의 식에서 칼만 이득($K_k$)이 작으면 $K_k(z_k - H\hat{x}_k^{-})$도 작은 값을 갖게 되어 추정값 계산에 거의 기여하지 못하게 된다.
반대로 예측값($\hat{x}_k^{-}$)이 추정값에 미치는 영향은 더 커지게 된다. 그런데 예측값은 이전 추정값에 비례하므로,
새로운 추정값에는 이전 추정값($\hat{x}_{k-1}$)이 주로 반영된다. 즉 칼만 이득이 작아지면, 추정값은 별로 변하지 않게 된다. 추정 오차가 충분히 작아져서 더 이상 추정값이 변하지 않는 상태로 수렴한 것 이다.
아래 그림으로 시간에 따른 칼만 이득의 변화를 볼 수 있다.
10.5 정리
이 장에서는 칼만 필터로 측정 잡음을 제거하는 문제를 다뤘다. 칼만 필터 알고리즘의 구현은 5장의 그림을 그대로 구현하는 것으로 충분했다. 오히려 문제에 맞는 시스템 모델을 선정 하는 게 더 어려웠다.