아래는 칼만 필터 알고리즘이다.
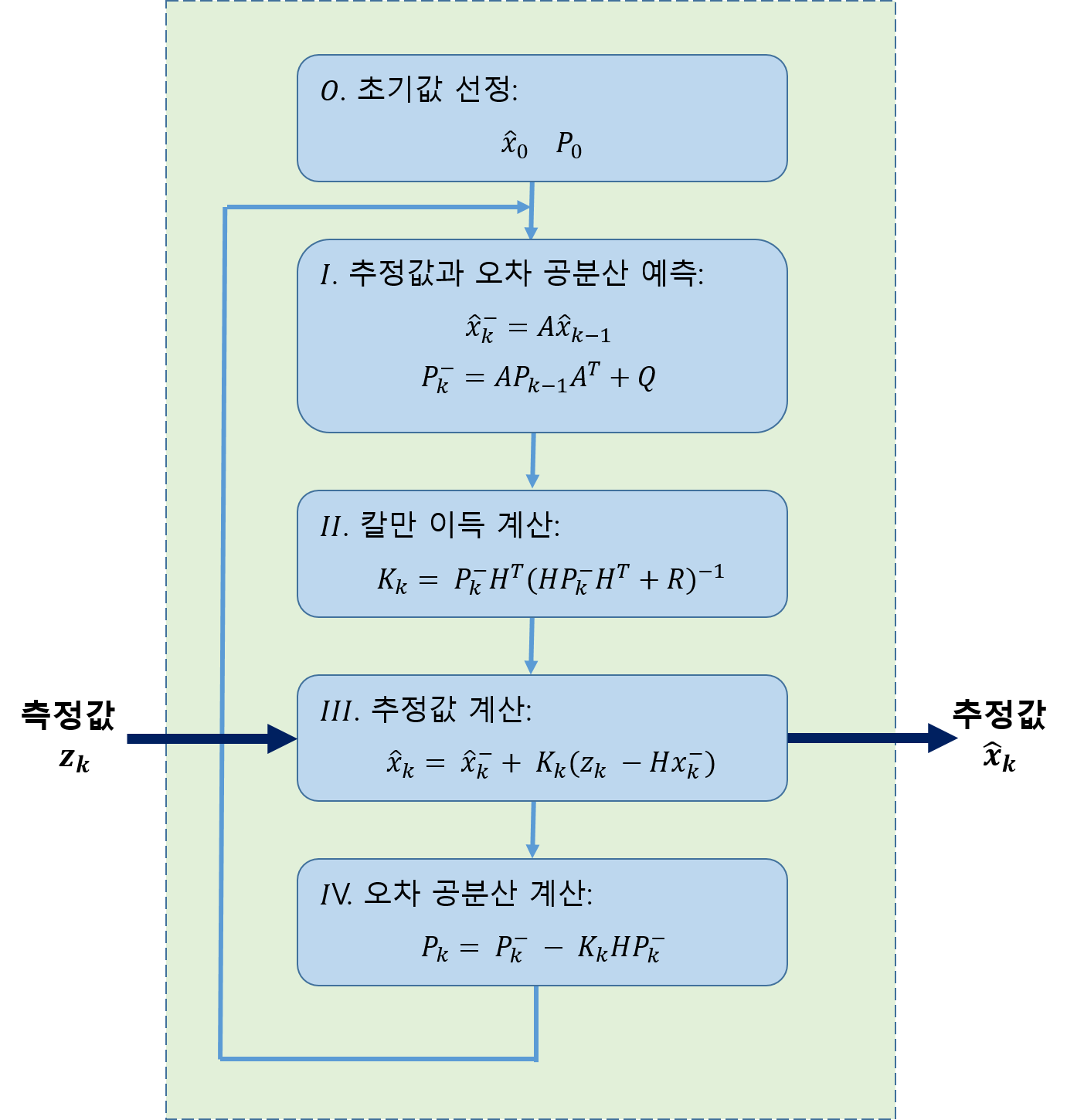
위 그림에서 점선으로 둘러싼 부분이 칼만 필터 알고리즘이다. 입력과 출력이 하나씩인 간단한 구조로, 측정값($z_k$)을 입력으로 받아 내부에서 처리한 다음 추정값($\hat{x}_k$)을 출력한다. 내부 계산은 총 네 단계에 걸쳐 이뤄진다.
참고로 위 알고리즘에서 $k$는 칼만 필터 알고리즘이 반복해서 수행된다는 점을 명시한다. 그리고 윗첨자 ‘$-$’의 의미는 중요하다. 윗첨자가 붙으면 이름이 같더라도 전혀 다른 변수를 의미한다. 윗첨자 ‘$-$’는 예측값을 의미한다.
그럼 알고리즘의 계산 과정을 구체적으로 살펴보겠다. 첫 번째 단계는 예측 단계이다. 이 단계에서는 $\textrm{II}~\textrm{IV}$단계에서 계속 사용하는 두 변수 $\hat{x}_k^{-}$와 $P_k^{-}$를 계산한다. 이 예측 단계는 시스템 모델과 밀접히 관련되어 있다.
$\textrm{II}$단계에서는 칼만 이득($K_k$)을 계산한다. 변수 $P_k^{-}$는 앞 단계에서 계산한 값을 사용한다. 그리고 $H$와 $R$은 칼만 필터 알고리즘 밖에서 미리 결정한다.
$\textrm{III}$단계에서는 입력된 측정값으로 추정값을 계산한다. 참고로 변수 $\hat{x}_k^{-}$는 $\textrm{I}$단계에서 계산한 값이다.
그 다음 $\textrm{IV}$단계는 오차 공분산을 구하는 단계이다. 오차 공분산은 추정값이 얼마나 정확한지를 알려주는 척도이다. 보통 오차 공분산을 검토해서 앞서 계산한 추정값을 믿고 쓸지 아니면 버릴지를 판단한다.
아래 칼만 필터 알고리즘에서 쓰이는 변수를 용도별로 구분했다.
외부 입력 : $z_k$ (측정값)
최종 출력 : $\hat{x}_k$ (추정값)
시스템 모델 : $A, H, Q, R$
내부 계산용 : $\hat{x}_k^{-}, P_k^{-}, P_k, K_k$
위 시스템 모델과 관련된 네 개의 변수 $A, H, Q, R$는 아직 설명하지 않았다. 이 변수들은 칼만 필터를 구현하기 전에 미리 결정해야 한다. 즉 칼만 필터 알고리즘에서 계산하거나 가정하는 값이 아니다. 이 값들은 대상 시스템과 칼만 필터를 사용하는 목적에 따라 설계자가 사전에 확정한다. 따라서 칼만 필터 알고리즘 자체를 공부할 때는 이 변수들은 이미 알고 있는 값으로 가정하고 신경 쓰지 않아도 된다. 하지만 칼만 필터의 성능에는 중요한 영향을 미치는 값이다.
위 변수들에서 시스템 모델과 관련된 변수를 제외한 나머지 변수들은 설계자가 임의로 변경할 수 없다. 측정되거나 알고리즘에서 계산하는 값이기 떄문이다. 따라서 설계한 칼만 필터의 성능이 원하는 만큼 나오지 않을 때, 설계자가 조정할 수 있는 변수는 시스템 모델과 관련된 네 개의 변수뿐이다. 즉 시스템 모델의 네 변수가 칼만 필터의 설계 인자가 된다. 이 값을 어떻게 선정하느냐에 따라 칼만 필터의 성능이 달라지게 된다. 그리고 시스템 모델이 실제 시스템과 가까울수록 칼만 필터의 성능은 좋아진다.
칼만 필터 알고리즘은 계산 과정이 네 단계로 되어 있지만, 의미를 기준으로 나누면 크게 두 단계로 분류된다.
- 예측 과정
맨 위 그림에서 $\textrm{I}$단계가 여기에 해당된다. 오차 공분산($P_{k-1}$), 직전 추정값($\hat{x}_{k-1}$)을 입력으로 받아서, 최종 결과로 예측값($\hat{x}_k, P_k^{-}$)을 내놓는다. 이 값들은 추정 과정에 사용된다. 예측 과정에서 사용하는 시스템 모델 변수는 $A$와 $Q$이다.
- 추정 과정
칼만 필터 알고리즘에서 $\textrm{II}$단계, $\textrm{III}$단계, $\textrm{IV}$단계가 여기에 속한다. 추정 과정의 결과물은 추정값($\hat{x}_k$)과 오차 공분산($P_k$)이다. 입력 값으로는 예측 과정의 예측값($\hat{x}_k^{-}, P_k^{-}$) 뿐만 아니라, 측정값($z_k$)을 전달 받아 사용한다. 추정 과정에서 사용하는 시스템 모델 변수는 $H$와 $R$이다.
정리하면 칼만 필터 알고리즘은 다음과 같다.
1. 시스템 모델($A, Q$)을 기초로 다음 시각에 상태와 오차 공분산이 어떤 값이 될지를 예측한다. : $\hat{x}_k^{-}, P_k^{-}$
2. 측정값과 예측값 차이를 보상해서 새로운 추정값을 계산한다. 이 추정값이 칼만 필터의 최종 결과물이다. : $\hat{x}_k, P_k$
3. 위 두 과정을 반복한다.