이 장에서는 칼만 필터 알고리즘의 추정 과정에 대해 알아 보겠다. 추정 과정에는 앞 장 그림의 $\textrm{II} ~ \textrm{IV}$단계가 해당된다. 추정 과정의 목표는 칼만 필터의 최종 결과물인 추정값을 계산해내는 것이다.
추정 과정의 추정값 계산식을 저주파 통과 필터와 관련 지어 설명하겠다. 칼만 필터의 추정값 계산 과정이 1차 저주파 통과 필터의 개념과 연결되어 있다는 사실을 확인한다. 이렇게 관련지어 이해하면, 칼만 필터 알고리즘의 기본 원리를 파악하는데 도움이 된다.
6.1 추정값 계산
$\textrm{III}$단계인 추정값 계산부터 시작한다. 추정값을 계산하는 식을 따로 떼어내서 살펴보자.
여기서 $z_k$는 측정값을 뜻하고, $\hat{x}_k^{-}$는 예측값을 의미한다. 예측값이 무엇인지는 다음 장에서 자세히 설명한다. 지금은 1차 저주파 통과 필터의 직전 추정값에 해당한다는 값으로 알아두자.
그럼 식 $\ref{6.1}$이 의미하는 바를 좀 더 자세히 살펴보겠다. 식을 전개해서 다시 정리해보자.
마지막 식을 자세히 보면 어디서 많이 본 것 같다. $H$를 단위행렬(identity matrix, I)로 가정하고 위의 식을 다시 써보겠다.
수식이 좀 더 간결해졌다. 이 수식은 3장에서 다룬 1차 저주파 통과 필터의 수식과 비슷하다.
이제 이 식에 $\alpha = 1 - K$를 대입해서 다시 정리하자.
이 식을 칼만 필터의 추정값 계산식인 식 $\ref{6.3}$과 비교해 보자.
두 식의 모양이 매우 비슷하다! 1차 저주파 통과 필터는 직전 추정값과 측정값에 가중치를 주고 더해서 추정값을 계산한다. 칼만 필터도 거의 비슷하다. 예측값($\hat{x}_k^{-}$)과 측정값($z_k$)에 적절한 가중치를 곱한 다음, 두 값을 더해서 최종 추정값을 계산한다. 직전 추정값 대신 예측값을 사용한다는 점만 다를 뿐, 가중치를 부여하는 방식까지 똑같다.
6.2 변하는 가중치
앞에서 칼만 필터의 추정값 계산식이 1차 저주파 필터와 아주 비슷하다는 점을 이야기했다. 그렇다고 두 수식이 완전히 똑같은 것은 아니다. 우선 칼만 필터의 식을 간결하게 하기 위해 $H$가 단위행렬이라고 가정했다. 이 덕분에 칼만 필터의 추정값 계산식이 1차 저주파 통과 필터와 거의 똑같은 형태를 가지게 된 것이다. 그런데 실제 문제에서는 이런 가정이 성립하지 않는 경우가 많다. 그렇다고 앞 절에서 무리한 가정을 도입해 억지로 끼워 맞추기를 한 것은 아니다. $H$가 단위행렬이라는 가정이 없더라도 칼만 필터의 추정값 계산식이 1차 저주파 통과 필터와 비슷한 사실은 여전히 유효하다.
이제 본론으로 들어가 보자. 여기선 1차 저주파 통과 필터와 구별되는, 칼만 필터만의 독특한 특징을 하나 소개한다. 먼저 칼만 필터가 새로운 추정값을 계산하기 위해 필요한 값들이 무엇인지 검토해 보자. 식 $\ref{6.1}$을 다시 옮겨와 보자.
우선 예측값($\hat{x}_k^{-}$)과 새로운 측정값($z_k$)이 있어야 한다. 저주파 통과 필터와 마찬가지로 칼만 필터도 재귀 필터이니 당연한 이야기이다. 측정값은 입력으로 받으니까 아는 값이다. 예측값은 다음 장에서 다룰 예측 과정에서 계산한 값을 전달 받는다. 그리고 $H$는 시스템 모델과 관련있는 행렬인데, 시스템 모델은 칼만 필터를 구현하기 전에 미리 확정되므로 역시 값이 주어진다. ($H$ 행렬에 대해서는 $8$ 장에서 설명한다.)
그렇다면 이제 남은 변수는 $K_k$뿐이다. $K_k$는 칼만 이득(Kalman gain)이라고 불리는 변수인데, 이 값만 알면 새로운 추정값을 계산할 수 있다.
그럼 $K_k$는 어떻게 구할까? 앞 장 그림의 $\textrm{II}$단계에 $K_k$를 계산하는 수식이 나와 있다.
이 식을 자세이 설명하지는 않는다. 칼만 필터를 사용할 때 이 식에서 특별히 주의해야 할 내용은 없다. 식 $\ref{6.4}$로 계산한 칼만 이득이 $\textrm{III}$단계의 추정값 계산 과정에서 가중치로 사용된다는 점만 기억하면 된다.
1차 저주파 필터에서는 추정값 계산에 사용되는 가중치($\alpha$)가 상수였다. 그래서 매번 가중치를 새로 계산할 필요가 없었다. 더구나 그 값을 결정할 때도 체계적인 방법에 따라 계산하는 것이 아니라, 필터 설계자가 임의로 적절한 값을 선정했다. 반면 칼만 필터는 알고리즘을 반복하면서 $K_k$값을 새로 계산한다. 즉 추정값을 계산하는 가중치를 매번 다시 조정한다. 이 점이 바로 칼만 필터가 저주파 통과 필터와 결정적으로 다른 점이다.
내용을 정리해보면, 칼만 필터는 1차 저주파 통과 필터와 비슷한 방식으로 추정값을 계산한다. 그런데 가중치를 조절하는 칼만 이득은 고정되어 있지 않고, 일정한 공식에 따라 매번 새로 계산된다. 즉 상황에 따라 추정값 계산식의 가중치가 계속 바뀐다.
6.3 오차 공분산
앞 장 그림의 칼만 필터 알고리즘에서 $\textrm{II}$단계와 $\textrm{III}$에 대한 설명을 모두 마쳤다. 이제 추정 과정의 마지막 단계인 공분산에 대해 알아보겠다. $\textrm{IV}$단계는 수식 하나만 계산하면 된다.
이 식에서 특별히 주목해야 할 점은 없다. 그냥 공식대로 오차 공분산을 계산해서 예측 과정으로 넘겨 주면 된다. 중요한 것은 오차 공분산의 의미이다. 오차 공분산은 칼만 필터의 추정값이 참 값에서 얼마나 차이가 나는지를 나타낸다. 다시 말해 오차 공분산은 추정값의 정확도에 대한 척도가 된다. $P_k$가 크면 추정 오차가 크고, $P_k$가 작으면 추정 오차도 작다. 이런 이유로 칼만 필터를 구현할 때 추정값과 함께 오차 공분산도 출력으로 내보내는 경우가 종종 있다.
오차 공분산의 의미를 간단히 짚고 넘어가겠다. $x_k$와 추정값($\hat{x}_k$), 오차 공분산($P_k$) 사이에는 다음과 같은 관계가 성립힌다.
변수 $x_k$가 평균이 $\hat{x}_k$이고 공분산이 $P_k$인 정규분포(normal distribution)를 따른다는 뜻인데, 여기에는 상당히 심오한 의미가 담겨 있다. 칼만 필터는 변수 $x_k$의 추정값에 대한 확률분포를 따져서 가장 확률이 높은 값을 추정값으로 선택한다는 의미이다.
갑자기 정규분포라는 말이 튀어 나왔는데 아래 그림과 같이 $x_k$가 가질 수 있는 값의 확률을 그려보면 종 모양의 분포가 된다는 의미이다. 이 분포에서는 평균이 가장 확률이 높다. 그리고 종 모양의 폭은 $P_k$가 결정한다.
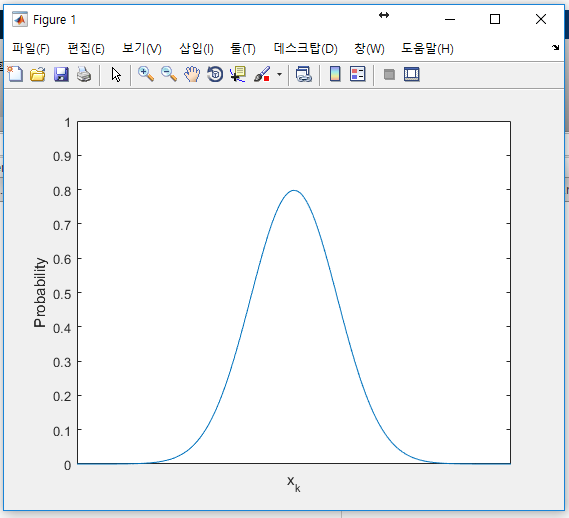
$P_k$가 추정값의 오차를 나타내는 지표가 되는 까닭도 이제 알 수 있다. 위 정규분포에서 종 모양의 폭이 좁으면 $x_k$가 가질 수 있는 값이 대부분 평균 근처로 모여 있게 된다. 그런데 평균이 추정값이니까 추정 오차가 작을 수 밖에 없다. 반면 종이 넓게 퍼진 모양이 되면 $x_k$가 가질 가능성이 있는 값의 범위도 넓어져 추정 오차도 커지게 된다.
참고로 오차 공분산은 다음과 같이 정의된다.
이 식에서 $E$와 중괄호의 의미는 중괄호 안에 있는 변수의 평균을 구하는 연산자이다. 그런데 우변의 $x_k - \hat{x}_k$는 참값과 추정값의 차이, 즉 추정 오차를 의미한다. 다시 말해 오차 공분산은 추정 오차의 제곱을 평균한 값을 의미한다. 오차 공분산의 크기와 추정 오차가 비례 관계인 이유가 바로 여기에 있다.
6.4 정리
이 장의 내용을 요약해 보겠다. 칼만 필터는 1차 저주파 통과 필터와 비슷한 방식으로 추정값을 계산한다. 다른 점은 가중치 역할을 하는 칼만 이득을 매번 새로 계산한다는 점이다. 그리고 칼만 필터 알고리즘에서는 추정값의 오차 공분산도 매번 계산하는데, 이 값이 추정값의 정확도를 나타내는 지표 역할을 한다.