예측 과정은 5장의 칼만 필터 알고리즘에서 $\textrm{I}$단계에 해당된다. 여러 단계를 거쳐야 하는 추정 과정보다는 절차가 훨씬 간단하다.
7.1 예측값 계산
예측 과정에서는 시각이 $t_k$에서 $t_{k+1}$로 바뀔 때, 추정값이 어떻게 변하는지를 추측한다. 즉 다음 시각 $t_{k+1}$에서 현재 시각의 추정값($\hat{x}_k$)이 어떤 값이 될지를 예측한다.
5장의 $\textrm{I}$단계의 수식을 옮겨 써보겠다. 식 $\ref{7.1}$이 추정값을 예측하는 식이고, 식 $\ref{7.2}$는 오차 공분산을 예측하는 관계식이다. 아래 식이 어떻게 나왔는지는 몰라도 된다. 그냥 기계적으로 구현하면 된다. 유도 과정을 아는 것보다는 예측값과 추정값의 차이를 이해하는 게 더 중요하다.
여기서 $\hat{x}_k$와 $P_k$는 $\textrm{III}$단계와 $\textrm{IV}$에서 계산한 값이다. 그리고 $A$와 $Q$는 시스템 모델에 이미 정의되어 있다.
위의 식에서 눈 여겨 봐야 할 부분은 예측값의 표기이다. 시각 $t_{k+1}$에서의 값이라는 의미에서 아래첨자 ‘$k+1$’을 붙이고, 예측한 값이라는 표기로 윗첨자 ‘$-$’를 붙였다. 윗첨자를 붙인 이유는 같은 시각의 추정값과 구별하기 위해서이다. 추정값과 오차 공분산을 제외한 다른 변수들은 이런 구분이 필요 없다. 왜냐면 예측하지 않기 때문이다. 아래에 추정값과 오차 공분산에 관련된 표기법과 의미를 정리했다.
7.2 예측과 추정의 차이
예측값을 어떻게 계산하고 표기하는지는 설명했으니, 예측과 추정의 차이점을 알아보자. 먼저 1차 저주파 통과 필터의 추정값 계산식을 옮겨 써보자.
중간에 별도의 단계를 거치지 않고, 새로운 추정값 계산에 직전 추정값($\overline{x_{k-1}}$)을 바로 사용한다. 즉 시각 $t_{k-1}$에서 $t_k$로 이동할 때 직전 추정값에 어떤 변화도 주지 않는다. $t_{k-1}$의 추정값 $\overline{x_{k-1}}$이 다음 시각 $t_k$의 계산에 그대로 사용된다. 아래 그림에 이러한 과정을 그렸다.
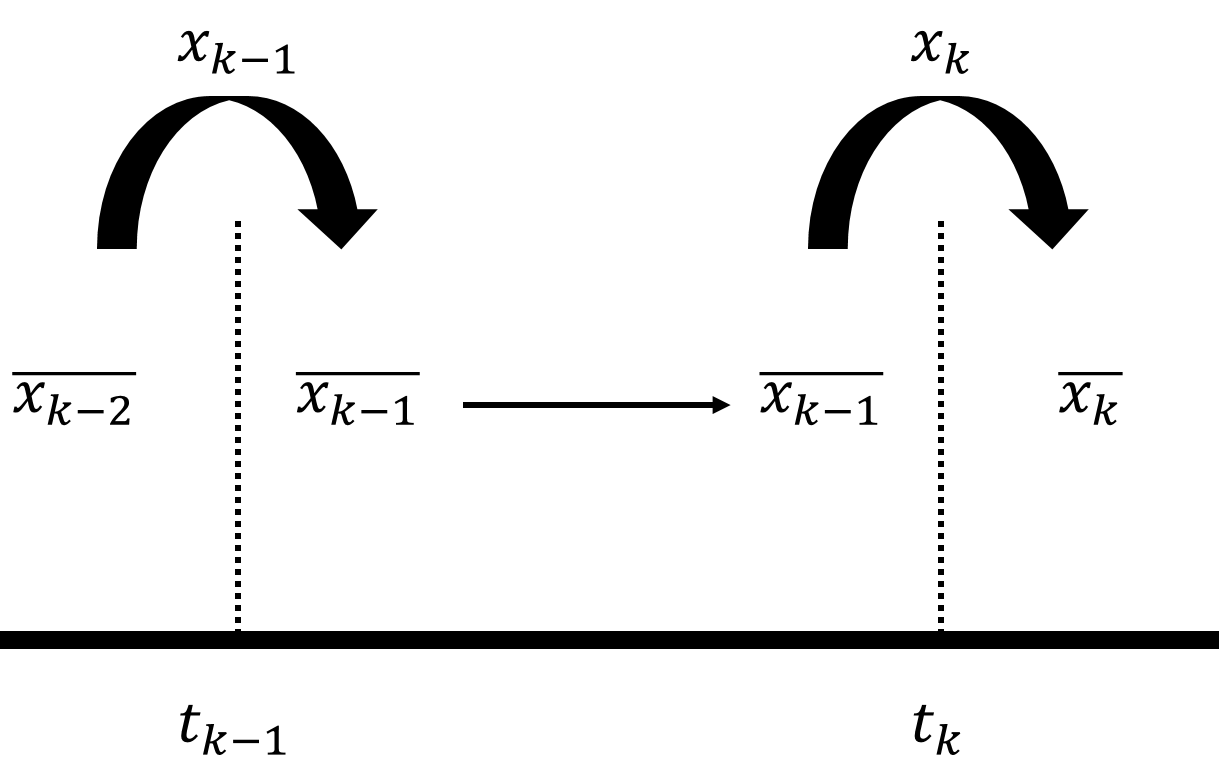
이제 칼만 필터의 추정값 계산식을 살펴보겠다.
직전 추정값($\hat{x}_{k-1}$)은 보이지 않고, 대신 예측값($\hat{x}_k^{-}$)이 그 자리를 차지하고 있다. 그런데 이 예측값은 직전 추정값을 이용해 구한 값이다. 앞 절의 식 $\ref{7.1}$을 보면 예측값($\hat{x}_k^{-}$)은 다음과 같이 구한다.
이 식을 위의 추정값 계산식에 대입해 보자.
이제야 직전 추정값이 보인다. 이처럼 칼만 필터는 1차 저주파 통과 필터와 달리 추정값을 계산할 때 직전 추정값을 바로 쓰지 않고 예측 단계를 한 번 더 거친다. 이런 이유로 예측값을 사전 추정값(priori estimate), 추정값을 사후 추정값(a posteriori estimate)이라고 부르기도 한다. 예측과 추정 과정의 관계를 아래 그림에 정리했다.
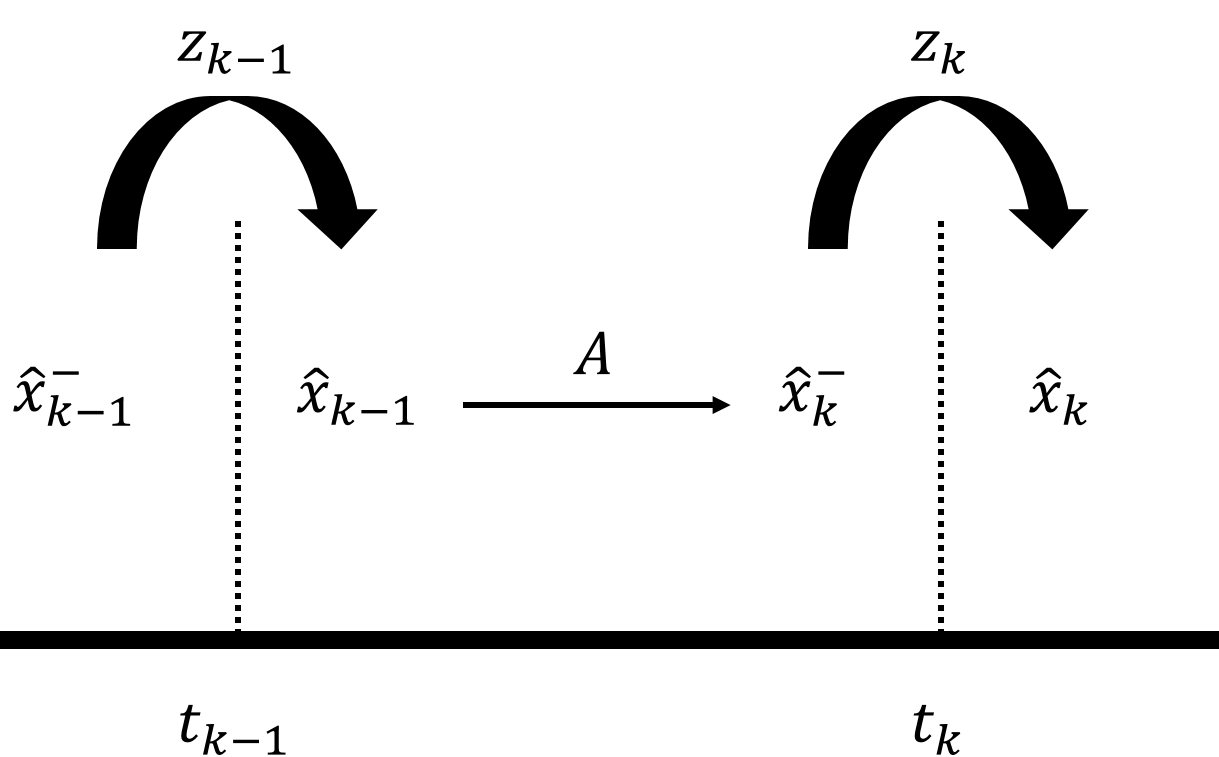
위 그림에서 측정값을 받아 계산하는 과정(둥근 화살표)이 ‘추정’이고, 다음시각으로 이동하면서 행렬 $A$를 거치는 과정(직선 화살표)이 ‘예측’이다. 1차 저주파 통과 필터와 달리 예측 과정 때문에 직전 추정값이 다른 값(예측값)으로 바뀐다. 그 결과 같은 시각에 두 개의 값이 존재하는데, 추정 과정의 결과인 오른쪽에 있는 값이 칼만 필터의 최종 출력이 된다.
7.3 추정값 계산식의 재해석
예측 단계의 계산식은 비교적 간단하지만, 칼만 필터의 성능에는 상당한 영향을 준다. 그 이유를 알아보자. 먼저 칼만 필터 추정값 계산식에서 우변의 마지막 항을 살펴보자.
이 식에서 $H\hat{x}_k^{-}$는 예측값으로 계산한 측정값을 뜻한다. 다시 말해 측정값의 예측값을 의미한다. 그렇다면 $z_k - H\hat{x}_k^{-}$는 실제 측정값과 예측한 측정값의 차이, 즉 측정값의 예측 오차가 된다. 이러한 분석을 토대로 위의 식을 해석하면, ‘칼만 필터는 측정값의 예측 오차로 예측값을 적절히 보정해서 최종 추정값을 계산한다.’ 라고 말할 수 있다. 이때 칼만 이득은 예측값을 얼마나 보정할지를 결정하는 인자가 된다.
이처럼 추정값 계산식을 예측값의 보정 관점에서 보면, 추정값이 성능에 가장 큰 영향을 주는 요인은 예측값의 정확성이다. 예측값이 부정확하면 아무리 칼만 이득을 잘 선정한다고 해도 추정값이 부정확할 수 밖에 없기 때문이다. 그런데 식 $\ref{7.1}$과 $\ref{7.2}$의 예측 계산식을 보면, 추정값과 시스템 모델의 $A$와 $Q$가 사용되는데, 이 두 변수가 예측값에 결정적 영향을 끼친다. 이 두행렬이 실제 시스템과 많이 다르면 예측값은 부정확하게 되고, 추정값도 엉뚱한 값을 갖게 된다.
따라서 칼만 필터의 성능은 시스템 모델에 달려있다고 해도 과언이 아니다. 시스템 모델이 실제 시스템과 얼마나 비슷한지에 따라 예측의 질이 달라지고, 예츠값에 따라 추정 성능도 좌우되기 때문이다. 이처럼 관건은 항상 시스템 모델이다.